
.png)
Executive Summary
Diagrid Cloud is a platform built and managed by Diagrid to simplify and enhance the use of Dapr (Distributed Application Runtime). Diagrid Cloud includes the infrastructure and software that powers Diagrid Catalyst, a product that allows developers to build and deploy distributed applications with ease through hosted developer APIs for things like service-to-service communication, state management and pub/sub messaging.
In this technical deep-dive, we will describe a recent architectural challenge we faced as a result of new requirements in Catalyst to handle dynamic resources with transient lifecycles in our Cloud control plane in addition to our existing declarative resources.
Highlights of this article include:
- Architectural evaluation and design for handling dynamic resources when building a cloud platform
- Comparison of eventing systems; NATS JetStream, Apache Kafka and Redis Streams
- Implementation details and lessons learned from using NATS JetStream for dynamic resource management
This article is aimed at software engineers and architects interested in modern cloud infrastructure and distributed systems. We'll share how we approached evolving our platform to handle these two distinct resource types and touch on lessons learned which may benefit others authoring similar systems.
Technical Context
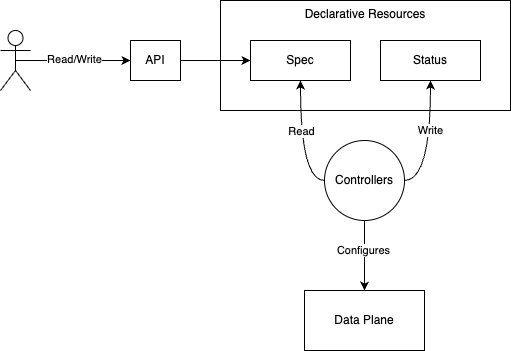
Declarative resources (sometimes called metadata) focus on describing the end state of a system or infrastructure, leaving the details of implementation to the underlying system. They are typically exposed via a REST-like API and processed by asynchronous API controllers.
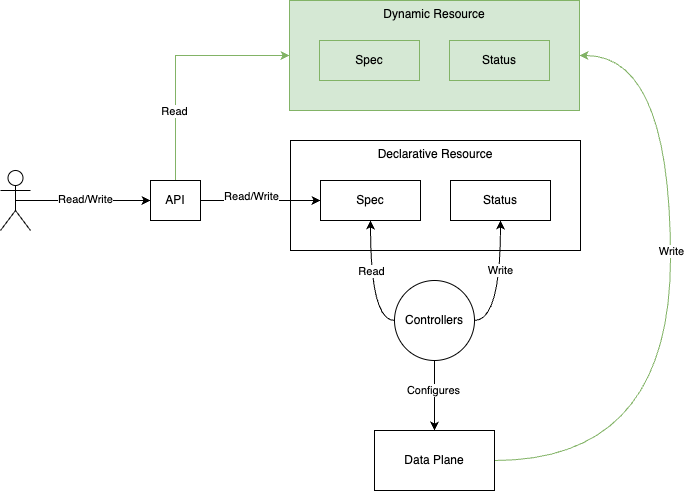
Dynamic resources, on the other hand, are more flexible and can be created or deleted on-demand in response to real-time system events, such as when a client opens a new connection to a data plane service.
Unlike declarative resources which are a form of user input to configure the system, dynamic resources are system feedback to the user of read-only resources that have been created by the system itself.
The Challenge
Diagrid Cloud was initially built with a management API that specifically handled declarative resources to allow users to manage entities within our cloud domain.
A few examples of entities managed within Diagrid Catalyst product are:
- Projects: Projects act as the security and network boundary for a set of Catalyst resources
- App IDs: Each App ID represents an externally-hosted application workload. An App ID is required for each microservice or application that will interact with the Catalyst APIs and aligns to a Dapr sidecar running on Kubernetes under-the-hood.
- Components: Components are a set of resources used to onboard backing infrastructure services into Catalyst so they can be used by the various APIs to perform work
Declarative resources like the ones above are persisted in a database along with an event log in our Cloud control plane. We then have regional agents that attempt to claim resources based on their suitability e.g. location, capability, etc. Once claimed, the agent runs controllers which will establish a gRPC stream to the control plane resources API over which it receives resources. This is implemented using a List and Watch mechanism similar to Kubernetes controllers.
For each resource, the controller performs a reconciliation to ensure that the local data plane is configured as desired and reports back status updates. The status updates include fields such as whether the resource is ready and can also include health statuses and other system generated data. This is a closed loop system by design. The intention of this system is to perform distributed reconciliation of declarative resources in our database and not to be used as a general purpose system monitoring agent. If the resource statuses indicate that the reconciliation is complete then the feedback loop is closed and no more processing is needed other than running a periodic re-sync.
In addition to the agent reconciliation system, we have a custom OpenTelemetry Collector that collects and forwards logs and metrics to our control plane to provide operational insights such as API logs, call latencies, etc.
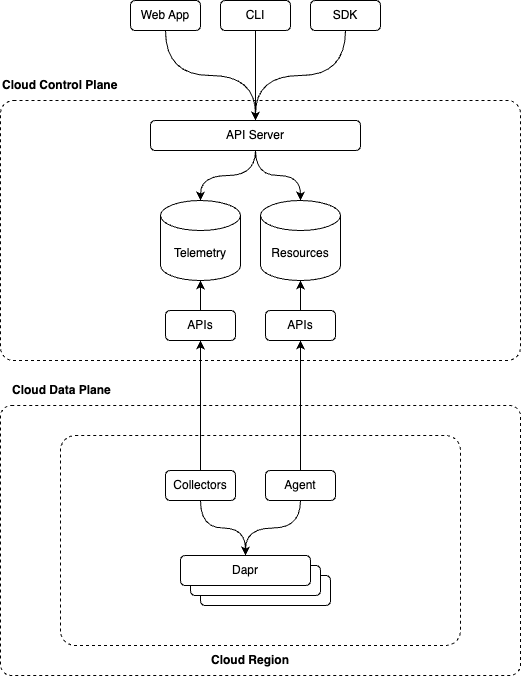
These 2 mechanisms are sufficient for the basic use case of provisioning cloud resources and providing insights into their operational health. However, what this system is not designed to handle is real-time event data emitted from the regional data planes.
In Diagrid Cloud we had a need to support 2 new use cases which fell into this category for Catalyst:
- Reporting the validation status of Dapr Components from each Dapr sidecar
- As mentioned above, when a user submits a create request for a new App ID in their Catalyst Project, our data plane provisions a corresponding Dapr sidecar instance behind the scenes. The user can then create Component resources which will be loaded by the underlying sidecars based on a primitive called scopes.
- Each Dapr instance will load any Dapr Components it is scoped to and then perform periodic validation to ensure they are valid. This status needs to be reported directly from the sidecar back into the system to inform the user that if a given component is healthy or not. This cannot be pre-validated outside of the sidecar as access to the infrastructure is tied to the identity of the sidecar itself.
- Representing Dapr streaming subscriptions for use with the Catalyst Pub/Sub API
- Catalyst exposes the Dapr Pub/Sub API which easily enables async messaging between applications via a simple API regardless of the underlying Pub/Sub component used. Traditionally, users would use declarative subscription resources to represent the desired subscription. However, as of Dapr 1.15, a user can dynamically subscribe at runtime via their application code.
- When a user’s application connects to the Dapr streaming subscription API we need the sidecar to report that a new dynamic streaming subscription has been created so we can include it in our management API when the user list subscriptions. This gives the user a unified view of their declarative and streaming subscriptions regardless of how they were created.
The above scenarios and a few others led to a new requirement for our system: the need to allow our APIs to access dynamic resources that were generated by the system itself and unify those resources with existing declarative resources as shown below.
The Options
Once this requirement became clear, we spent time considering a few possible approaches, taking into account factors like timeline, management overhead, performance, and more.
Use Telemetry
Our team already had a mature telemetry pipeline available within our regional data plane so we considered whether we could use structured telemetry events via the OpenTelemetry API to flush these real-time events to our control plane.
We could simply extend the logger inside the Dapr runtime to log events to our OpenTelemetry Collector via either push or pull protocols. The OpenTelemetry Collector can be configured with a write ahead log (WAL) to recover events after a crash that have not yet been pushed to the external storage. Once the telemetry data is stored in our control plane telemetry storage engine, it can be made available to query from our API services.
In the end, we found the quality of service, performance, and consistency we could achieve via the telemetry pipeline was not sufficient for our use cases.
Use our Cloud control plane API directly
An alternative approach we considered was to have the Dapr sidecar directly call our existing control plane API to create the dynamic resources in the same way a user would when taking a declarative approach. However, this was not desirable as the system initiated resources actually require different behavior than user initiated resources. For example, we do not require any reconciliation or processing of the system initiated (dynamic) resources, instead we just need them to be included as read-only entries in the API response. Dynamic resources also have a much more transient lifecycle than user-configured resources and therefore the storage requirements for each differs.
Use Eventing
Ultimately, we did not want to abuse an existing system to support behavior for which it was not designed. Instead, we decided to use a purpose-built eventing system which would allow us to send events when certain things occurred in the system, such as a new gRPC subscription stream being connected.
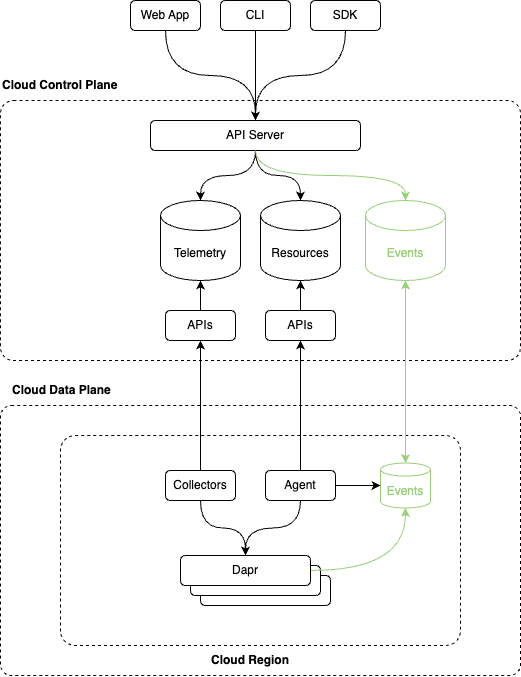
We wanted this eventing system to be regionally redundant so that if the control plane went offline, we would have persistence at the regional level. We needed our control plane APIs to be able to query this data easily to combine it with the declarative data from the database. For latency and availability reasons, this API query would ideally access the data locally within the control plane. This meant we needed a system that would allow us to persist the data locally in the region while also synchronizing the data to a queryable store in the control plane. We also wanted the system to have the semantics of an event log and not a message broker because we wanted event replay and to potentially support multiple consumer groups in the control plane for different purposes.
For these reasons, we considered the following technologies:
The Evaluation
Apache Kafka
Apache Kafka is a distributed event streaming platform that acts as a high-throughput log system. It is designed for fault-tolerant, durable, and scalable storage of events. Kafka stores streams of records (events) in topics, where each event is persisted in order and can be replayed by consumers at any point in the log.
Key Features:
- Durability: Events are persisted on disk and can be retained indefinitely or for a configurable period.
- High Throughput: Kafka is optimized for high-throughput use cases, making it ideal for large-scale data pipelines.
- Consumer Replay: Consumers can rewind and replay events from any point in the log, supporting long-term event storage and analysis.
- Distributed & Scalable: Kafka scales horizontally and is capable of handling massive volumes of events.
Kafka is ideal for large-scale stream processing, event-driven architectures, and log-based data pipelines where high throughput, durability, and long-term storage are required.
NATS JetStream
NATS JetStream is a high-performance event streaming and messaging system that builds on NATS. JetStream offers persistent message storage, message replay, and event stream processing. It is designed to be simple, lightweight, and optimized for low-latency messaging.
Key Features:
- Low Latency: NATS is known for ultra-low latency, making JetStream ideal for real-time event streaming.
- Durability: JetStream provides message persistence with configurable retention policies and supports event replay.
- Scalability: While NATS can handle high-throughput use cases, it is simpler and more flexible compared to Kafka, with easier horizontal scaling.
- Lightweight: NATS is designed to be simple to deploy and manage, with a smaller operational footprint compared to Kafka.
- Rich APIs: NATS ****has built in API abstractions such as the key-value store or object store which allow clients to directly query the streams without have to materialize the data in another store.
JetStream is well-suited for real-time messaging, event-driven applications, and scenarios where low latency and simplicity are critical. It’s also a great choice for cloud-native environments and microservices.
Redis Streams
Redis Streams is a log-based data structure built on top of Redis, designed for event-driven architectures. It supports persistent message logs and can be used for real-time stream processing.
- Key Features:
- Low Latency: Redis is known for its high-speed in-memory performance, making Redis Streams very low-latency.
- Message Persistence: Redis Streams supports persistence (to disk), allowing it to act as a message queue with event logs.
- Consumer Groups: Redis Streams allows multiple consumers to read from a stream in parallel using consumer groups.
- Simplicity: Redis Streams is part of the Redis ecosystem, so it integrates seamlessly with other Redis features and has a straightforward setup.
Redis Streams is ideal for low-latency, high-throughput, real-time event processing where in-memory performance is critical. It is better suited for smaller-scale systems or systems that already use Redis.
Decision
After evaluating our options, we chose NATS JetStream for several key reasons. Its low-latency performance and built-in key-value store APIs aligned perfectly with our need to efficiently query dynamic resources from our control plane which drastically reduced upfront development cost.
The lightweight nature of NATS made it simpler to deploy and operate compared to Apache Kafka, while still providing the durability and event replay capabilities we required. Additionally, its cloud-native design philosophy matched our infrastructure well, making it ideal for our microservices architecture.
While Apache Kafka would have provided similar capabilities, it would have been over-engineered for our use case, and Redis Streams lacked the distributed nature we needed for our multi-region deployment.
The Solution
Topology
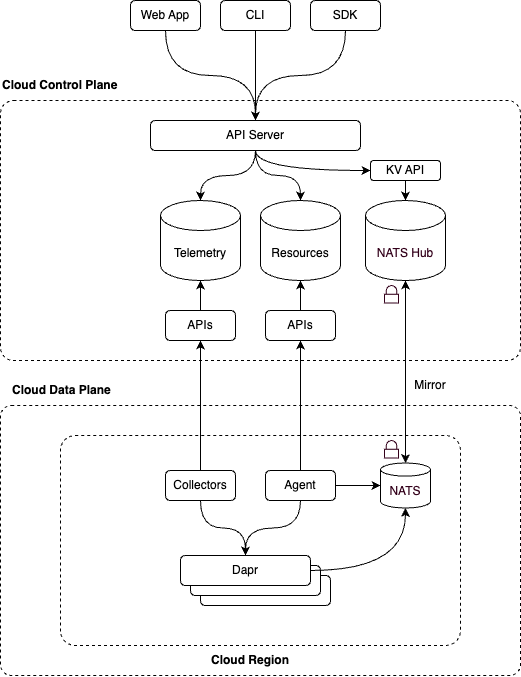
We setup NATS using a leaf and hub topology. Each Cloud Region deploys a new NATS leaf node which can receive the events from the local regional services such as the Catalyst Agent or Dapr instances. We then connect the regional leaf to the associated Cloud control plane Hub cluster to make the events available to our API services.
The NATS Hub cluster can synchronize streams from many different leaf clusters and supports a flexible subject-based routing mechanism that allows you to organize your event streams effectively.
We then made use of the native key/value API that NATS provides over the streams to access the data we needed in our API services. This meant that we did not need to materialize the events into another key/value store as would be required with other eventing systems. The NATS key/value API provides basic data access functionality which, when paired with the subject-based routing, allowed us to satisfy both of our required use cases.
Authentication and Authorization
To authenticate and authorize services in our data plane to our control plane we rely heavily on strong attestable identities via SPIFFE and mutual TLS (mTLS). When we introduced NATS to our architecture, we didn’t want to compromise on security by using basic username/password credentials.
Fortunately for us, NATS provides support for authorization via SVID URIs and so we just had to figure out how to integrate the nodes with our existing PKI and workload identities. For this, we decided to build a utility that we could deploy as a sidecar container to the NATS container which would fetch the identity from our identity provider (Idp) and then pass it to NATS to use as it’s client certificate. The sidecar is responsible for renewing the identity credential periodically.
Use Cases
Streaming Susbcriptions
To handle showing dynamic streaming subscription in our API, we updated our custom Dapr sidecars to publish an event whenever a new gRPC streaming subscription was connected. The NATS key/value API also supports applying a Time-To-Live (TTL) to the keys. We leveraged this by setting a short TTL on the key and having the sidecars periodically re-acknowledge the connection to keep the key alive. If the connection is gracefully closed we can explicitly remove the key, if it is ungracefully closed, the key will expire shortly after.
Component Validation Status
In order to display dynamic component validation status in our API, we integrated with the Dapr component system so that it could publish events capturing the validation status at startup and periodically during the sidecar’s lifetime.
In Dapr, a component can be loaded by multiple sidecars which could lead to different validation statuses being reported from each. Therefore, we added logic in our APIs to reconcile all of the statuses into a coherent view of the component health.
Keyspaces
When using the NATS key/value API, you need to design your keyspace to work for your use case. You can include dot (.) dividers in your keys to imply a hierarchal structure. This structure can then be leveraged by readers of the key value bucket by using pattern matching. For our use cases, we used the key structure <org-id>.<region-id>.<project-id>.<resource-type>.<resource-id> which allows our consuming API services to query by project using wildcard patterns such as <org-id>.<region-id>.<project-id>.components.* to fetch all component resources in a project. This same pattern was also used to handle dynamic subscriptions as they too are modeled as project level resources.
Conclusion
By leveraging NATS JetStream’s lightweight architecture, built-in key/value API, and cloud-native flexibility, we’ve created a robust, secure, and scalable platform for dynamic resource management in Diagrid Cloud, which has empowered new capabilities and features in our Catalyst product. For developers and architects tackling similar challenges, we hope our journey offers practical insights which can help guide your architectural decisions.
If you are interested in trying out the new features we’ve added as a result of these platform changes, try out Diagrid Catalyst to explore how our platform empowers teams to build resilient, distributed applications with ease.




