introducing the new dapr jobs API and scheduler service
The Dapr 1.14 release last month included many new capabilities and was feature packed, this included the addition of a new Jobs API and Scheduler control plane service for managing jobs.
Cassie Coyle
Contributor
Overview
The Dapr 1.14 release last month included many new capabilities and was feature packed, this included the addition of a new Jobs API and Scheduler control plane service for managing jobs. Over the years, the Dapr project was often requested to include a Jobs API. The Scheduler service enables this, and is designed to address the performance and scalability improvements on Actor reminders and the Workflow API. In this post, I am going to deep dive into the details of how the Scheduler service was designed and its implementation to give you some background.
Prior to v1.14 if you wanted to schedule a job you could use the Cron binding component to implement recurring jobs on a regular defined schedule, such as automating database backups, sending out recurring email notifications, running routine maintenance tasks, data processing and ETL, running system updates and batch processing, as examples. However, the binding approach lacked in the areas of durability and scalability, and more importantly, could not be combined with other Dapr APIs. For example, another frequent request is to be able to have delayed messages for pub/sub, and there will undoubtedly be other delayed jobs scenarios that will emerge.
Sitting behind the Jobs API in the Dapr control plane is the Scheduler service, which runs in both Kubernetes and self-hosted modes. This Scheduler service stores the jobs scheduled by an application and sends them back at trigger time, so the application can perform business logic accordingly. The Scheduler service also significantly improves the scalability and performance of Actor reminders, which are used by the Workflow API, by orders of magnitude!
Jobs API
Let’s dive into the Jobs API. A job is a single unit of execution with data that represents a task or function to be triggered at a specified future time or at some recurring schedule. A job does not have a status associated with it meaning there is no status of ‘started’, ‘stopped’, ‘pending’, ‘running’, etc. From a developer perspective, the application schedules a job with a data payload that will be received in the future at trigger time. A job is never invoked before the schedule is due, but a ceiling time is not guaranteed on when the job is invoked after the due time is reached. The jobs that are created are stored in the Scheduler service which handles the orchestration logic of when to send the job back to the application. See the diagram below that illustrates how this all works.
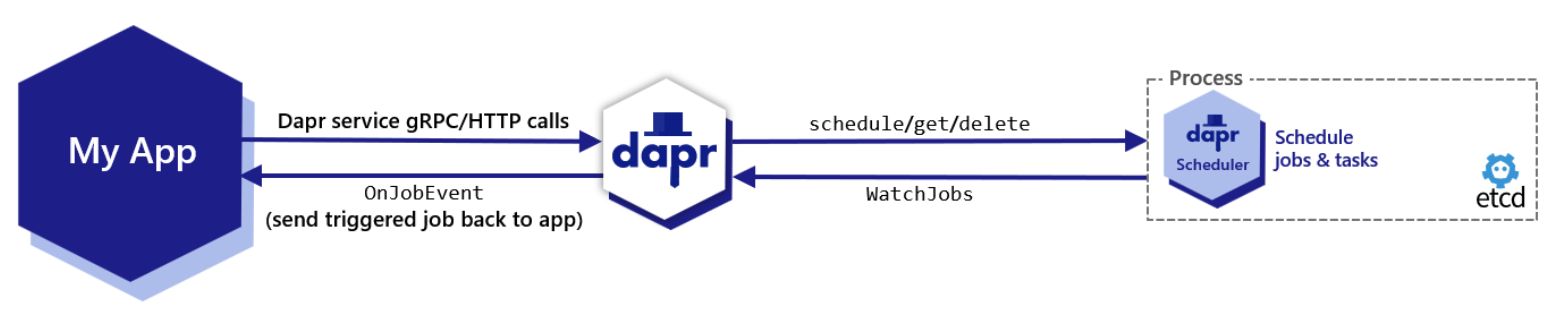
The call to schedule a job from an application to Dapr via the Alpha API endpoint is a simple unary call, either via gRPC or HTTP. The Dapr sidecar then receives the job with its relevant job details, including but not limited to: name, schedule, repeats, data, duetime. The sidecar then attaches the namespace and appID and sends the job to the Scheduler service. The Dapr sidecar round-robins the CRUD requests equally to all Schedulers available, if multiple are running. Yes, you can have more than one Scheduler service.
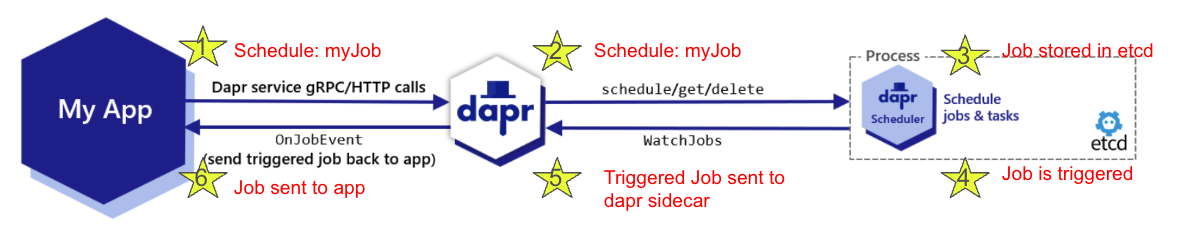
The job lives inside the Scheduler until its trigger time, at which point it is sent back to the Dapr sidecar via a streaming connection. The Dapr sidecar then sends the triggered job back to the application via a simple unary call - using the OnJobEvent endpoint for gRPC or the /job/ endpoint for HTTP. Once the application receives the job callback at trigger time, then the business logic for that job is executed. You can see an example of the flow of scheduling a job called myJob and receiving it at trigger time in the diagram below.
Show me the code
Let’s take a look at how to schedule a job and handle it at trigger time with some Go code to perform a crucial production database backup. I should point out that as of the v1.14 release, only the Dapr Go SDK has support for the Jobs APIs, with the others coming later this year. If you want to contribute to the other Dapr SDKs, your help is very much appreciated.
From your application code you add the job event handler providing the job name and function to be executed at trigger time, and schedule a job by providing the job name, schedule, repeats, data, duetime. It is worth noting that the endpoint used to schedule a job is synonymous with creating a job. A job is inherently scheduled once it is created, so the term for ‘creating a job’ is the same as ‘scheduling a job’ because you are unable to create a job without it being scheduled under the hood.
Below is a snippet of Go code for how that might look to schedule a prod-db-backup job and receive it at trigger time performing business logic once the job is received. In a real scenario, the job schedule field should be adjusted accordingly.
if err = server.AddJobEventHandler("prod-db-backup", prodDBBackupHandler); err != nil {
log.Fatalf("failed to register job event handler: %v", err)
}
job := daprc.Job{
Name: "prod-db-backup",
Schedule: "@every 1s",
Repeats: 10,
Data: &anypb.Any{
Value: jobData,
},
}
err = client.ScheduleJobAlpha1(ctx, &job)
if err != nil {
panic(err)
}Get Started with the Jobs API
You can try the Jobs API with the Dapr Quickstart sample here. Or instead, the code from the above example can be found in the go-sdk examples here.
You can also use Diagrid Conductor Free on your Kubernetes cluster to monitor the Scheduler service. Find out more here.
Scheduler Control Plane Service
Let’s now turn our attention to the Schedule service. The Scheduler control plane service is a new process in v1.14 that is deployed by default in addition to the existing Dapr control plane services. It can be run as a single instance or in high availability (HA) mode, with 1 or 3 instances, respectively. The Scheduler service stores jobs to be triggered at some point in the future, guaranteeing that a job is triggered by only one Scheduler instance. The Scheduler guarantees at least once job execution with a bias towards durability and horizontal scalability over precision, partly due to the desire to scale the Dapr Workflow API.
Implementation-wise, when run in Kubernetes mode the Scheduler runs as a StatefulSet, specifically as a headless service allowing each pod to have a stable network identity enabling predictable names to reference the pods by. The Scheduler contains an embedded etcd instance that is responsible for storing the jobs, which requires no additional configuration. This makes it suitable for both local developments in self-hosted mode and in highly available deployments in Kubernetes. By default data persists to a Persistent Volume Claim using the cluster’s default storage class. etcd is sequentially consistent, which is the strongest consistency guarantee available from distributed systems. All Scheduler instances, each one running with an embedded etcd instance inside, have complete access to all jobs that have been scheduled across all instances. This is true as of now, however there will be a proposal with a design that will likely change this for scaling out beyond 3 instances going forward, where it will likely share etcd instances amongst the Schedulers since there is little gain beyond 3 etcd instances. Then those additional Schedulers would become stateless.
Let's look at an example of how to view running the Scheduler in HA mode, as shown in the diagram. Notice how each Scheduler has its own etcd and all the etcd’s communicate with each other such that all of them contain the complete set of all jobs:
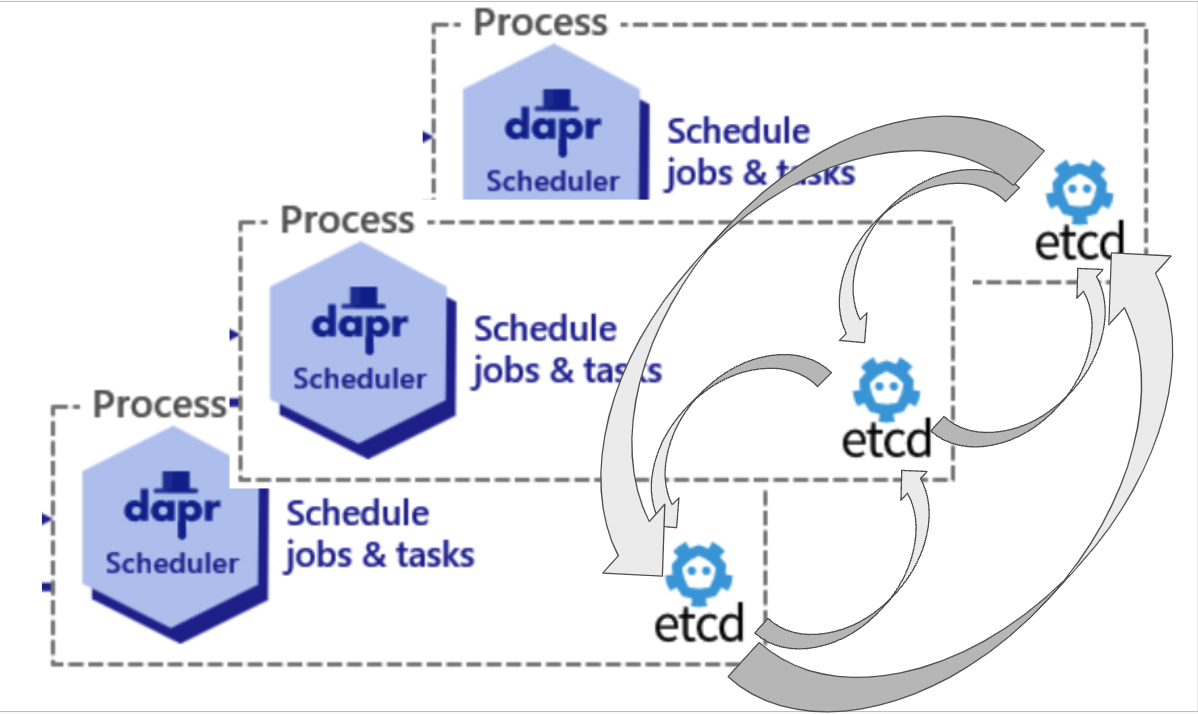
All etcd instances have the same data replicated across instances. Jobs scheduled from the Jobs API, Actor reminders, and Workflow API can be seen below in the table showcasing etcd data records:

Scheduler: Distributed Job Management and Horizontal Scaling
How does this work under the covers? The Scheduler internally runs a cron scheduler, a library created for the Scheduler to manage the distributed and orchestration aspect of the jobs in a fault tolerant way. What I mean by this is that the go-etcd-cron library, written in go, was designed specifically for distributed environments where there are several instances running concurrently acting on these shared jobs that live in the embedded etcd instance inside each Scheduler. Upon startup, the Schedulers announce themselves such that they know how many replicas there are in total which is important because it is used as an ownership table to equally split up the jobs amongst all the Schedulers. Since all Schedulers have all jobs in their etcd instances, to ensure we have only one Scheduler sending a single job back, the jobs are evenly divided such that each Scheduler owns a subset of the jobs to send back to the Dapr sidecar at trigger time. The Schedulers achieve horizontal scaling because as new instances are added or removed, the job ownership is dynamically recalculated. This ensures that each Scheduler instance continues to own an equal subset of all jobs in etcd, maintaining load balance and efficient processing. All Schedulers are considered equal and there is no concept of leadership amongst instances; each Scheduler shares the responsibility equally. However, etcd, which is used for consistent storage, does perform a leader election internally. This is necessary for etcd’s consensus algorithm, ensuring that only one instance is responsible for coordinating writes, maintaining data consistency across all replicas. Despite etcd’s internal leader election, all Schedulers remain equal in their handling of job assignments. Each Scheduler owns a subset of the jobs, enabling effective load sharing of triggered jobs.
Upon a Dapr sidecar starting, it connects to all Schedulers via a streaming connection. All Dapr sidecars connect to all Schedulers because based on the internals of the Scheduler the job ownership amongst Schedulers it is not known which Scheduler owns which jobs so the Dapr sidecars have to watch all Schedulers for the triggered job. The Schedulers manage a connection pool of Dapr sidecars based on namespace and appID to send jobs back on. Due to all sidecars connecting to all Schedulers, the job can be sent back to any of the same appID instances. At trigger time, meaning once the job has reached its scheduled time to be sent back to the application, the Scheduler sends the job back to the Dapr sidecar by round robining between the available instances in the connection pool for that appID.
Using Scheduler to Store Actor Reminders
Let’s now touch on another use case for the Scheduler service, and that is with improving the scale of Actor reminders. You can now create SchedulerReminders as a preview feature in Dapr as of 1.14. And to clarify, SchedulerReminders has nothing to do with the Jobs API. SchedulerReminders refers to the use of Actor reminders stored inside the Scheduler. The current (prior to v1.14) Actor reminder system, which was stored in memory, limited scalability and performance as the number of reminders grew, leading to bottlenecks and reliability issues. When SchedulerReminders is enabled, all reminders are stored in the Scheduler service. This means Actor reminders as well as the reminders used for Workflow under the hood are stored in Scheduler. When the SchedulerReminders are enabled this is the only reminder system that is used. Only one reminder system can be used at a time.
All scheduled jobs are stored in the Scheduler. That means that if you use the Jobs API then all those jobs live in the Scheduler, and SchedulerReminders, also reside in the Scheduler. See the table above to understand how these records look in etcd.
To use SchedulerReminders apply a configuration file to your applications. See below for an example of the configuration:
apiVersion: dapr.io/v1alpha1
kind: Configuration
metadata:
name: myconfig
spec:
features:
- name: SchedulerReminders
enabled: trueShow me the numbers. Performance Gains Using the Scheduler
The Scheduler significantly enhances both the scalability and stability of Actor reminders, including those used with Dapr Workflows. In Dapr, there was a known limitation with using Workflow with the current reminder system where it could only achieve horizontal scaling to no more than two instances of Dapr sidecars or application pods. At that point the concurrency of the workflow execution would drop. Using Scheduler as the underlying Actor reminder system, improved throughput and scale.
In testing we measured performance improvements of 71% for parallel workflows iterations, where “iterations” refers to the number of workflow executions processed in parallel, with a max concurrent count of 60-90, whereas the current Actor reminder system performance would drop by 44%. Additionally, during a high scale test, with 350 max concurrent workflows and 1400 iterations, we saw performance improvements that were 50% higher than the existing reminder system. Furthermore, Oliver Tomlinson from Dotmatics, showcased the monitor workflow pattern using Scheduler with 1 application and 1000 workflows taking 5 minutes 5 seconds. When he scaled that same application to 5 instances with 1000 workflows, it finished executing in 1 minute 23 seconds. He has also demonstrated more specific performance improvements in the Dapr v1.14 celebration, available on YouTube to watch here. The Scheduler has the potential to scale to millions of jobs and is at most limited by the storage in etcd. Further performance numbers can be found in the comments here.
Conclusion
The introduction of the Jobs API and Scheduler control plane service in Dapr 1.14 represents a major leap forward in job management and scalability for Actor reminders and the Workflow API. By extending the highly used cron binding approach, the Jobs API introduces a more versatile and efficient way to manage scheduled tasks. The Scheduler service offers a robust solution for managing jobs with enhanced performance and scalability, laying the groundwork for a more stable and scalable Workflow API in Dapr 1.15. By integrating the Scheduler with the new Jobs API, Actor reminders and the Workflow API, Dapr now provides a unified, fault-tolerant system for scheduling and managing jobs, ensuring greater efficiency and reliability.
If you have any questions about the Jobs API or the Scheduler Service, please join the Dapr Discord and use the #jobs-scheduling channel under the APIS category.