Operationalizing LLM Interactions with Dapr's New Conversation API
Dapr 1.15 introduces a new API that standardizes LLM provider interactions while handling critical cross-cutting concerns, including prompt-caching and PII obfuscation.
Bilgin Ibryam
Principal Product Manager
The Dapr Conversation API offers a different approach: a unified interface for LLM interactions that handles common challenges while still addressing cross-cutting operational concerns such as observability and retries. This article explores how Dapr simplifies LLM integration, with complete code examples available on GitHub.
The multi-LLM integration challenge
Organizations building LLM-powered applications face a complex reality — there's no one-size-fits-all provider or model. Different LLMs excel at different tasks, vary in cost, and offer different deployment options. Even within a single provider, you might want to use GPT-4 for complex reasoning in production but GPT-3.5 for development due to cost. With new models being released frequently, teams need the flexibility to experiment with and adopt newer, more cost-effective models without code changes. This multi-LLM reality creates several operational challenges:
- Provider and Model Flexibility: Reduce code changes while consuming LLM APIs across multiple providers and use cases.
- Security & Privacy: Protect applications, models, and data from inappropriate access.
- Reliability: LLM API calls can fail for various reasons - rate limits, timeouts, temporary. overloading is common. How to handle rate limits, timeouts, and service disruptions gracefully.
- Cost and Performance: Optimize response times and reduce API costs through caching.
- Observability: Understanding what's happening with your LLM interactions across different providers and apps requires consistent logging, metrics, and tracing.
LLM interactions are part of the well-known distributed app challenges that often cross team boundaries. Integrating with LLM provider SDKs forces every team to solve these challenges independently, leading to duplicated effort and inconsistent implementations. What's needed is an abstraction layer that handles these common concerns while preserving provider-specific capabilities. This is precisely what Dapr's new Conversation API delivers.
Unified LLM access with Dapr conversation API
The Dapr Conversation API brings the same benefits to LLM interactions that Dapr provides for other distributed system components. Instead of every team implementing their own provider integrations, error handling, and security and observability concerns, you get a consistent API that works across multiple LLM providers and programming languages.
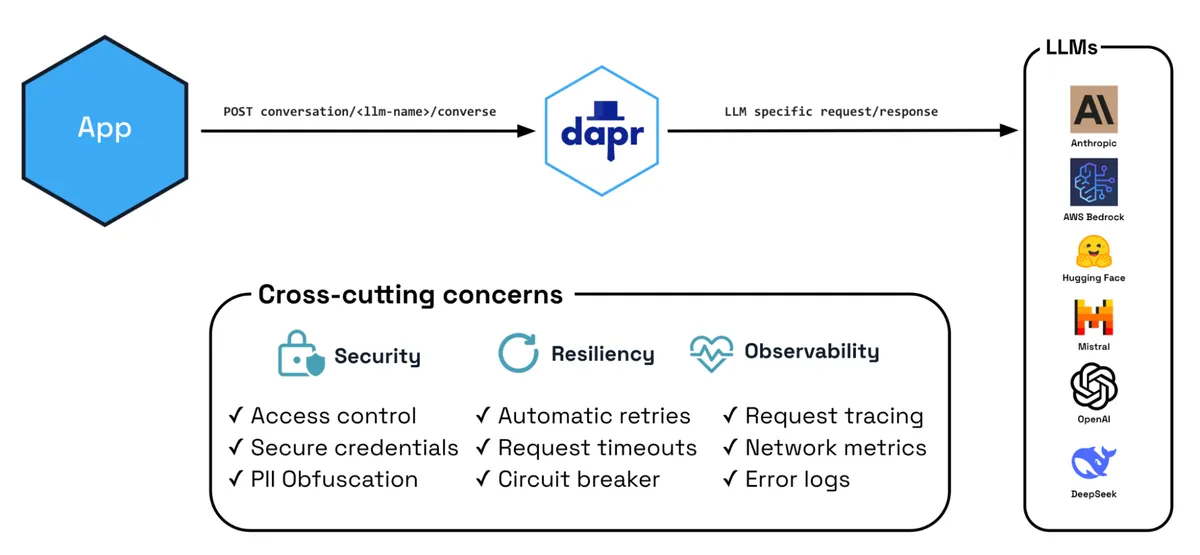
Dapr Conversation API Overview
When your application wants to interact with an LLM, instead of integrating directly with each provider's SDK, you:
- Configure a Dapr conversation component that specifies your LLM provider
- Use the Dapr Conversation API from any supported language SDK or plain HTTP/gRPC
- Let Dapr handle the provider-specific implementation details
Let’s look at an example. For local testing, the built-in echo component simply returns your prompts:
I can start a Dapr sidecar with this component using Dapr CLI, the following way:
Then interact with configured LLMs is directly via HTTP where the component is in in the URL (here I’m using the REST Client extension in my IDE):
The Conversation API supports multiple popular LLM providers including OpenAI, Anthropic, AWS Bedrock, Hugging Face, Mistral, and DeepSeek. If you want to add your favorite provider the Dapr project actively encourages contributions and it is very easy to build a new Conversation component in the component-contrib repo. Each provider component can be configured with provider-specific options like model selection and API keys, but your application code remains the same regardless of which provider you're using. For example, to use a real LLM simply provide your component configuration. For example, using the OpenAI component:
The Conversation API includes a built-in caching mechanism (enabled by the cacheTTL parameter) that optimizes both performance and cost by storing previous model responses for faster delivery to repetitive requests. This is particularly valuable in service environments where similar prompt patterns occur frequently. When caching is enabled, Dapr:
- Creates a deterministic hash of the prompt text and all configuration parameters
- Checks if a valid cached response exists for this hash within the time period, for example the last 10 minutes
- Returns the cached response immediately if found, or makes the API call if not
This approach reduces latency and costs for repeated prompts. Unlike provider-specific caching mechanisms (which typically still charge a percentage of the original cost), Dapr's caching works consistently across all providers and models, completely eliminating the external API call. The cache exists entirely within your runtime environment, with each Dapr sidecar maintaining its own local cache.
Enterprise-grade security
Securing LLM interactions requires multiple layers of protection, from controlling which applications can access models to protecting sensitive data in transit.
Access control
Enterprise environments have strict granular control requirements for accessing models. Among many security features, Dapr provides component scoping that restricts which applications can access specific LLM providers and models:
The component example above, ensures that only the authorized application (secure-app)can access an expensive or sensitive model (named in this example, giving operations teams confidence that model usage aligns with business priorities.
The following request would only work when executed by the scoped secure-app:
And fails from any other app.
Secret management
Additionally, in the example above, you can also see how Dapr handles API key security. Storing credentials directly in component definitions is a security risk, so Dapr's secret management integration lets you reference LLM credentials from secure vaults:
Dapr supports multiple secret stores including Kubernetes Secrets, Azure Key Vault, AWS Secret Manager, HashiCorp Vault, and others - allowing your team to follow security best practices with minimal effort. The example above uses_localsecretstore which simplifies local development by loading secrets from the local file system._
Automatic PII obfuscation
When working with LLMs, preventing leakage of Personally Identifiable Information (PII) is critical, especially in regulated industries. The Conversation API includes automatic PII obfuscation for both incoming and outgoing data, providing an essential security layer. The feature identifies and obfuscates sensitive information like credit card numbers, phone numbers, email addresses, physical addresses, SSNs, and various identifiers before they reach the LLM provider. This feature is enabled with a simple flag in the requests.
Let’s explore this capability using the .NET SDK, one of the supported SDKs (.NET, Go, Python, with Java and JavaScript support coming soon):
Install the dependencies with: dotnet build And run the example app together with the sidecar and its component definition:
The scrubbing is done by the Dapr runtime, ensuring sensitive information never leaves your environment. For example, "My email is user@example.com" becomes "My email is [EMAIL_ADDRESS]" before being sent to the LLM provider, protecting your users' data while preserving the semantic intent of the prompt.
Building resilient LLM interactions
The value of the Conversation API extends far beyond provider abstraction. By leveraging Dapr's existing enterprise-grade features, operations teams can turn LLM interactions into reliable, secure, and observable parts of their production systems.
LLM providers impose strict rate limits, with popular models frequently experiencing overload and additional throttling. Service outages and network instability further complicate reliable integration. With Dapr's resiliency policies, you can apply robust retry logic, timeouts, and circuit breaking to your LLM calls without modifying application code.
Preventing runaway requests
LLM processing times can vary dramatically based on model complexity, prompt length, and provider load conditions. Without proper timeout management, requests can hang indefinitely, blocking threads, wasting resources, and creating poor user experiences.
Dapr's resiliency policies address this with configurable request timeouts:
This configuration ensures that requests exceeding the defined duration (60s) are automatically terminated, allowing you to gracefully handle errors or switch to an alternative, faster model.
When setting timeouts, consider the expected processing time for different models and request types. For example, GPT-4 typically responds to simple queries within a few seconds, while complex reasoning tasks (such as o1) or long-context prompts may require 30–60 seconds or more. Other models like Claude or Mistral may have different response characteristics. By carefully tuning timeout values, you can balance user experience expectations against the need for comprehensive responses.
Transient failure handling
LLM APIs often experience transient failures that can be rescued with a proper retry strategy. Dapr allows you to configure detailed retry policies that are particularly effective for LLM interactions. Here is a full resiliency policy containing the above timeout policy, together with retry and circuit breaker combined:
This policy targets specific HTTP status codes that are excellent candidates for retries:
- 429 (Too Many Requests): You've hit a rate limit that will reset after a brief pause
- 500 (Internal Server Error): Temporary server issue unrelated to your request
- 502 (Bad Gateway): Upstream server received an invalid response, often during cloud deployments
- 503 (Service Unavailable): Server temporarily unable to handle the request due to maintenance or load
- 504 (Gateway Timeout): Gateway timed out waiting for a response, common under heavy load
With exponential backoff, each retry attempt waits progressively longer, preventing network overload while maximizing the chance of eventual success. If all of that fails, but the model API is still unresponsive, the circuit breaker kicks in to prevent further requests for 5 mins and prevent additional system exhaustion.
Fail-fast protection
Some LLM service failures can't be resolved with simple retries. When an account gets locked due to payment issues, usage quotas are exhausted, or a provider experiences prolonged outages, continuing to send requests only compounds the problem. In these scenarios, it's better to fail fast and preserve system resources.
Circuit breakers address this challenge by monitoring for failure patterns. When a threshold of consecutive errors is detected, the "circuit opens" and immediately rejects subsequent requests. This prevents cascading failures, protects downstream systems, and allows your application to gracefully degrade its service or switch to an alternative provider. For a detailed example of circuit breaker configuration, see the Dapr resiliency documentation.
Operational visibility for LLM interactions
LLM applications require specialized visibility into LLM behavior extending beyond traditional system metrics. While AI-focused tools like LangFuse, LangSmith, BrainTrust, and others excel at evaluation-specific telemetry (model-as-judge testing, human feedback collection, prompt effectiveness, retrieval accuracy), they're designed for AI engineers and product teams rather than operations staff monitoring production systems.
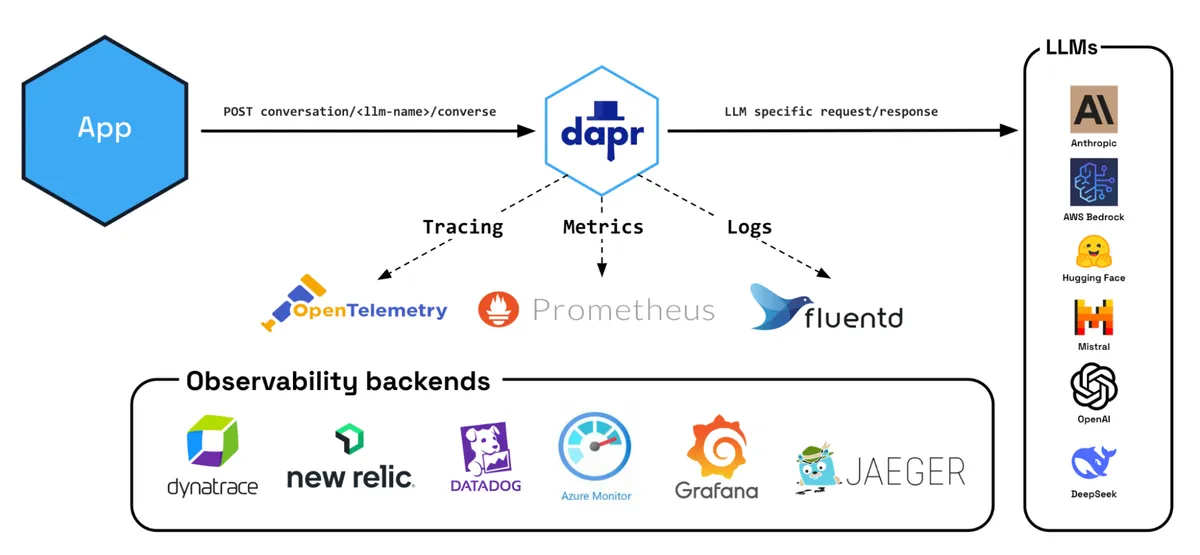
Dapr Observability Overview
SRE and operations teams have established tooling, alerting thresholds, and runbooks built around OpenTelemetry, Prometheus, and other industry-standard observability frameworks. Operations teams need LLM operations to integrate with these existing stacks. LLM interactions are just one component of end-to-end user experiences, and Dapr provides consistent observability for Conversation API calls using the same mechanisms it applies to all other interactions (state, pub/sub, workflow, etc.).
Enabling tracing in Dapr is straightforward:
With this configuration in place, when an application sends an LLM request through Dapr's Conversation API, a standard observability flow occurs:
- Dapr generates and propagates W3C trace context headers for each LLM conversation request
- These headers are added to the outgoing request to the LLM provider (OpenAI, Anthropic, etc.)
- When the response is received, Dapr completes the trace span
- Traces are sent to configured observability backends via openTelemetry protocol (Jaeger, Zipkin, etc.)
- Metrics are captured and exposed over the metrics API
- Any significant events such as errors are logged too.
This creates a complete picture where operations teams can trace a request from frontend through microservices and into the LLM provider, identifying bottlenecks and understanding exactly where and why failures occur in a format that integrates with their existing monitoring stack.
Beyond traces, Dapr automatically emits Prometheus metrics for LLM interactions, including request counts, latencies, and success/failure rates, that feed directly into Prometheus or other metrics systems for alerting and dashboards. Here is how these metrics could be rendered:
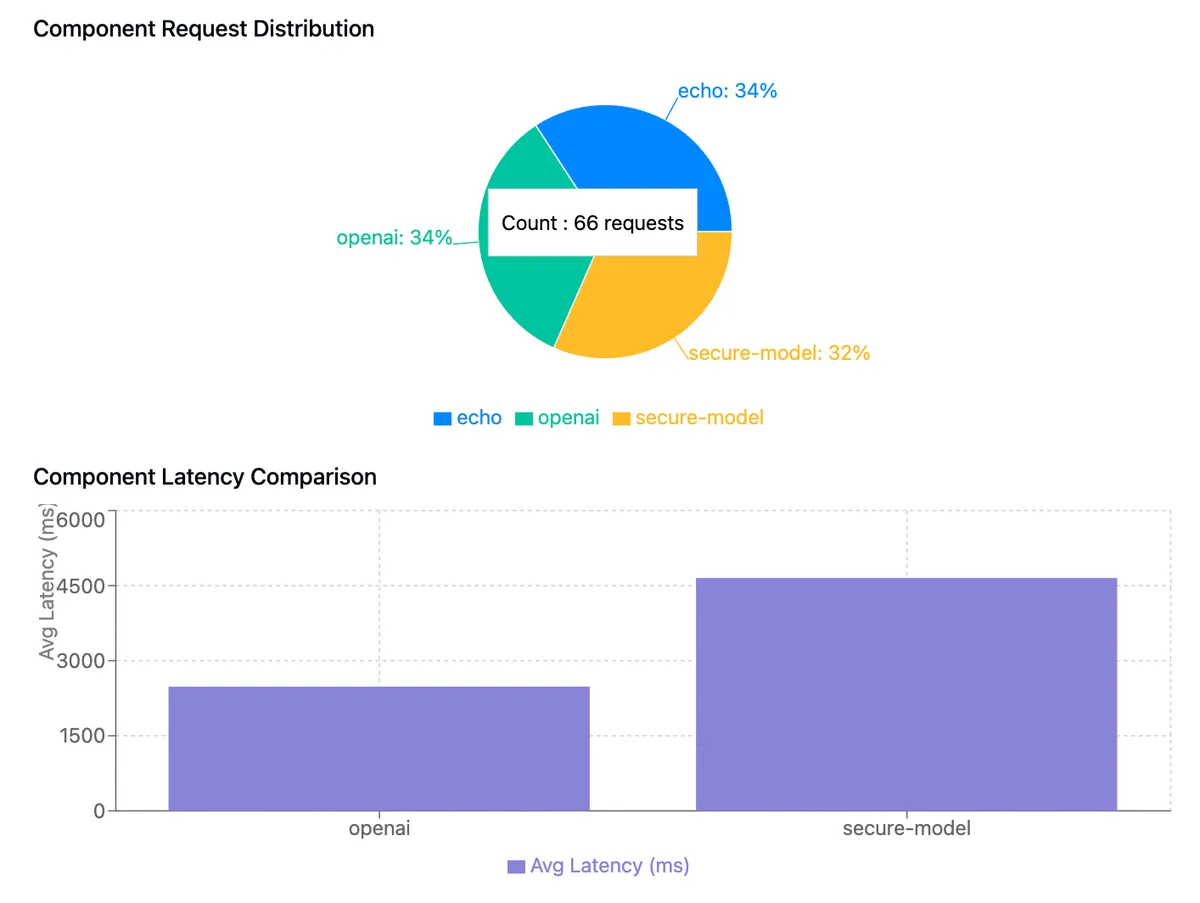
Visualization of Dapr conversation API metrics
Dapr also generates structured logs for every Conversation API call, capturing details like component name, model selected, request metadata, and any errors encountered—all in a consistent JSON format, ideal for easy parsing by log aggregation tools.
By implementing observability through industry-standard protocols like OpenTelemetry, W3C trace context, Prometheus metrics, and structured logging, Dapr ensures LLM operations aren't isolated from your existing monitoring infrastructure. This standards-based approach means operations teams can leverage their current observability stack (Jaeger, Zipkin, Prometheus, Grafana, Fluentd, etc.) without building and maintaining separate monitoring pipelines for AI components. The same dashboards, alerts, and runbooks that monitor your microservices can now seamlessly include LLM interactions as just another part of your distributed system.
The future of LLM applications with Dapr
Developing and deploying LLM-powered applications in production requires more than just API calls to model providers. As we've seen, the Dapr Conversation API transforms LLM interactions from potential operational blind spots into enterprise-ready, manageable components such as security, resiliency, observability, and more.
The Conversation API is just one part of Dapr's growing AI capabilities. For teams building more complex AI systems, Dapr Workflow and other Dapr APIs are used to create stateful agentic systems. These agents can be composed into agentic applications that perform multi-step tasks with built-in workflow orchestration, persistent state management, and the same operational advantages that the Conversation API provides.
The open-source Dapr community continues to evolve these capabilities based on real-world feedback. To get started with the Dapr Conversation API today, explore the Dapr documentation, try the companion code examples in our GitHub repository, and check out the Conversation API Quickstarts.
For production deployments, consider Diagrid Conductor, which provides enterprise-grade management for Dapr on Kubernetes with automated operations, security best practices enforcement, and comprehensive monitoring across all your clusters. For organizations requiring additional support, Diagrid also offers 24/7 production assistance with 1-hour response times, prioritized feature development, and timely CVE resolution through their Dapr open source enterprise support.
Every LLM-powered application involves solving the same integration problems: authentication, caching, error handling, observability, and security. Yet most teams are forced to rebuild these solutions for each provider they use, creating inconsistent implementations and increased maintenance overhead.
Ready to Go to Production?
Add durable execution to your AI agents in minutes. Start free, no credit card required.