When platform teams meet developers
Developers building with distributed applications for large organizations face many challenges. In this article the following are challenges are covered: Unreproducible and complex local environments, Slow feedback loops, Lack of standardized conventions and practices.
Mauricio Salatino
Staff Software Engineer
When organizations design, build, and maintain complex distributed applications, every challenge looks like an integration problem. With the rise of platform engineering in the Kubernetes and cloud-native space, these integration problems are hidden behind a set of APIs, dashboards, and helpers (like CLIs), which are intended to help developers overcome these integration challenges and focus on improving their applications.
In my personal experience, and after seeing the largest companies in the world describing their platform engineering activities, the following challenges are the ones that are currently tackled: service discovery & scaffolding, infrastructure provisioning, CI/CD, observability, and security.
While these are all very important topics, application developers and architects face additional challenges currently not prioritized by these platform engineering initiatives. In this article, I go over the most frequent challenges developers face when building with distributed applications working for large organizations with complex tech stacks. I’ll cover the following developer challenges:
- Unreproducible and complex local environments
- Slow feedback loops
- Lack of standardized conventions and practices
The developers’ mindset
To reach intermediate and senior levels, developers must focus on a specific technology stack. This means they must spend a fair amount of time working on projects involving specific tools. Each community, usually centered around a programming language or a specific industry, has its tools of choice that developers must master to be productive.
These tools will include learning an IDE or code editor, setting up projects to run, test, and debug them efficiently, and using Git or a source version control system to manage and share their changes with their teammates.
Once you feel confident with these tools, you must learn about the application architecture, which might be only a slice of the overall architecture relevant to your work. This learning involves understanding different services and their roles, different architectural patterns, service-to-service communication strategies (how do two services talk to each other), and application infrastructure to understand where data is stored, where configuration parameters are being picked up, and if asynchronous messaging is required.
This journey is challenging if the application domain is complex. With cloud services, cloud providers, and cloud native technologies, learning your application tech stack and tools for day-to-day development seems just a tiny fragment of the big picture. This pushes developers to divert their time to learning and gaining experience with tools not directly related to changing their applications. This “waste” of time is one of the reasons why most platform engineering initiatives include as a key point “reducing developer’s cognitive load”.
Working for a large financial institution
As a developer working for any large organization, you will be in charge of developing an application/service that runs on complex environments.
Imagine you work for a large multinational bank on two core services: the `monitoring accounts` and the `account notifications` services. These services track significant money movements in users' accounts and send notifications to users when these large transactions occur.

To do your daily work, you will need a specific setup and tools to be available in your workstation, including VPNs to securely connect to internal services and accounts to be created for you to access different systems (to track your work, request resources, etc.)

Once you have access to all the tools and environments, a discovery phase starts. In this phase, you need to learn about the surroundings of your immediate work, other services that are relevant or required for your application/service to work, how to troubleshoot when things go wrong, and probably who your main point of contact is when you are completely lost.
Once you get a task assigned, you will start working on it until you feel confident enough to make your first pull request / change request to the source version control system. Do you know which test to run before committing your code? What will the CI pipeline do to validate your changes? What can you do to reduce the waiting time between submitting your changes and the changes being validated? Do you need to notify someone about these changes? After waiting for a while, everything goes red. Guess what? You missed an indentation policy you were unaware of, causing your pull request to fail miserably.

The more you get used to your application, and as you start interacting with other teams, it will be natural to start creating libraries to share behavior across services. In most large organizations, these conventions are codified in libraries or pushed down to the infrastructure. While these libraries are developer-focused, who owns these libraries' lifecycles and when changes can be introduced that might impact several services are questions that will eventually pop up.

In this blog post, I wanted to step away from discussing your typical platform engineering practices and instead dig deeper into these other challenges that developers face and how platform engineers can help their fellow developers be more productive.
Top 3 development related challenges
This section covers three fundamental challenges to making your developers happy. Let’s go over them one by one to see how platform engineering teams can do more than just provide a self-service platform for teams to use to fix bottlenecks that slow down development teams proactively.
1. Unreproducible and complex local environments
If you cannot ensure that every developer in the project has the same setup, the same tools installed, and can run and debug their projects efficiently, then chaos is in your hands. To solve this challenge, platform engineering teams must understand which tools developers use, including their technology stack. This includes IDEs, runtimes, CLIs, and other configurations to guarantee that every developer can quickly run their projects to work.
The more the platform team understands what their developers are doing, the easier it will be to automate and replicate these setups to onboard new team members.

Let’s look at three different but similar examples:
- Java
- IntelliJ IDE for Java
- Git CLI
- Docker
- Maven (or Gradle) for dependency management
- Java Virtual Machine + Software Development Kit (Java SDK)
- Go
- GoLand
- Git CLI
- Docker
- Go Modules (it now comes with the runtime) for dependency management
- Go runtime
- Node.js
- VSCode
- Git CLI
- Docker
- NPM (or `yarn`) for dependency management
- Node JS runtime
Each tool has different versions that need to be managed across teams. Tools like IDEs support sharing coding standards that can be enforced by the IDE if configured correctly. IDEs also support plugins, depending on which frameworks your applications are using, that must be configured correctly to work with your projects.
As you can see, even if you manage to set up all the tools correctly on developers’ workstations, there are some shared services, such as private container registries and public services, such as plugin registries and licensing services, that developers must be able to interact with to perform their tasks.
In our bank example, both the monitoring accounts and the account notifications services are likely written using the same programming language and similar tooling. Let’s assume that this bank uses Java for a second, so most team members working on these services must have the same setup to avoid issues.

In most scenarios, the source code from the services will be cloned in each workstation, for that, the git CLI or UI will be configured with the team member account. When working with Maven for dependency management, it is a common practice to have a private artifact repository where these dependencies will be stored and fetched every time that a developer builds each service. Finally, Docker (and docker-compose) is commonly used for development tasks, such as bootstrap application infrastructure components.
In such scenarios, as a platform team you should try to discover where the friction is. Do developers have everything that they need to do their work in these two example services? What can go wrong? How are they keeping the version of the tools that they need aligned? Do each team create their own Docker Compose file to start infrastructure for the project that they need if there is a centralized effort to provide these configurations to different teams? How much time is lost in onboarding a new team member? Which accounts will need to be created for each developer? How are these accounts managed over time? What happens when a developer leaves the company? Or when a developer goes on holidays, do you need to shutdown environments that they were using?
Remember to think about simplicity from the application developer's side. Kubernetes adds an extra layer of complexity for developers to manage. When working with Kubernetes, we make these setups much more complicated. Even after ten years of Kubernetes, the question remains excellent: Do you want your developers to interact with Kubernetes daily? Pushing every developer to learn how to interact with a Kubernetes cluster might be challenging, and every community (Java, Node, .NET, Go) have their own specialized tooling to create more specific integrations to complement developers’ inner loops.

Tools that can help you to automate/simplify environments:
- DevPod: uses the Devcontainer.json specification to create containerized development environments you can share. Tools like this can help to tackle scenarios where having the right tools configured for all team members is getting in the way of productivity.
- NixOs / DevBox: With NixOS and tools like DevBox, you can create highly reproducible environments down to all their dependencies. I strongly believe NixOS is the way to go, but the entry cost was quite high, as in order to have a truly reproducible environment you need to manage every dependency down to the kernel that you are running. With Tools like DevBox the entry point becomes more manageable as they rely on trusted dependencies and can also export Devcontainer specifications.
- For Kubernetes, if your developers really need Kubernetes:
- KinD: provides an easy way to get a Kubernetes cluster up and running for local development tasks using just Docker.
- vcluster: can help you to enable developers to provision new virtual clusters on demand. This will allow platform teams to provide teams with a big shared cluster that can host any number of virtual clusters that can be configured with the applications and tools that these teams need to do their work.
Platform Engineering teams must work hard to understand what developers expect for their environments and provide the right tools to keep these environments simple and reproducible.
Here are a list of questions that platform engineering teams can ask to figure out how these environments should look like:
- Do you know which tech stack the application development teams are using?
- Do you know which frameworks, versions, and libraries they are using? Where are these frameworks hosted? How do they manage dependencies?
- Do you know/manage which IDE your developers use? How about the configurations for their IDEs?
- Do you know which CLIs (binaries in PATH) they use daily?
- Do you let developers clone source code manually? Is this automated? Do developers know how to sync and reset the working copies of their repositories?
- Which artifacts are cached locally vs redownloaded every time developers want to build or run their applications?
2. Slow feedback loops
If your developers spend a considerable amount of time waiting for pipelines to validate their changes, there is something to be done about it. The first step to reducing feedback loops is using the Practical Test Pyramid to have healthy conversations with your teams about which tests are executed and how. Understanding which tests can be executed locally before pushing code changes and how often CI pipelines fail can help developers refine their testing strategies.
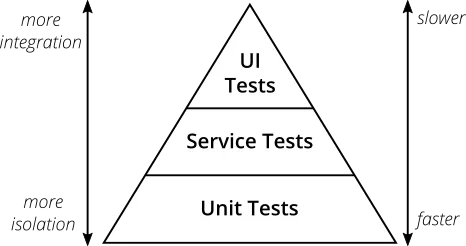
Can you, as a platform team, provide tools and conventions to reduce these feedback loops? The first step is gathering data about how many pull requests (changes) take to validate CI Pipelines before merges can happen. If this time is considerably large, you must investigate where most of it is used. Are developers running the same tests that CI is running? Can they, if they want to?
Following on #1, depending on what technology stack is being used for local development, what extra tools are being used to run integration, performance, and end-to-end tests on CI pipelines? Can we bring them closer to developers? With very powerful workstations, running all those pipelines locally can make sense if this reduces the waiting time for developers to validate their code changes.
If we go back to our bank example, imagine that you are using GitHub actions or a similar tool. Your CI/CD pipelines will overlap with the tools required for development, as our CI/CD pipelines will probably build, run, and test the changes that developers are making in the codebase.
It is vital to understand how much time developers spend waiting for CI/CD pipelines to do their job. Having clear metrics and reducing the differences between the tools that developers use in contrast with what the CI/CD pipelines are using, is key to improve environment parity.

It is no surprise that the CI/CD pipelines are similar to the set up in our workstations. Still, the key takeaway here is that every difference between your local development inner loop and your outer loop, including the CI/CD pipelines, costs your team's time. The usual suspects are the differences in the environments where the application runs. Is the CI/CD environment different from the environment where the developer runs the services for development purposes? Are they using Docker Compose to bootstrap application infrastructure such as the Database and Message Broker depicted in the previous diagram, are they using the same versions as the pipeline?
Examples of tools that can help you to ease the pain:
- GitHub Action: tons of organizations are using GitHub actions to run their CI and CD pipelines. While this provides an overall good experience, all these pipelines run in the cloud and require complex setups that are very difficult to reproduce locally. For some companies, this is not even an option and while there are several initiatives to have self-hosted runners or even running these pipelines locally there is no clear option, pushing platform teams to make complex decisions that will be hard to change down the line.
- Pull Requests bots: If you can help developers be more efficient, you should do so. Adding auto-formatting tools and/or auto-merge bots will automatically approve Pull Requests from trusted team members, freeing up their time to do more important things than just monitoring pipelines to see if everything is working as expected.
Dagger: Finally, Dagger is a tool created to make builds fast and reproducible regardless of the environment in which they run. The extra edge that gives Dagger an advantage from a developer angle is that it provides SDKs to create pipelines using tools developers already know. Their motto is “good-bye push and pray” highlighting the big-time waster that pipelines can be to developers.
Questions that might help platform teams create new strategies to reduce feedback loops:
- Do you have many flaky tests? This should be sorted out first
- Can you provide tools to help developers to run more checks locally?
- Are you collecting data about how many integration tests are failing in your pipelines?
- Do your integration tests require complex infrastructure provisioning that takes too much time? Can this be simplified?
- What are the main differences between the CI/CD pipeline environments and developer’s environments? Finding the differences might help to tackle future issues related with environment parity.
3. Lack of standardized conventions and practices
Complex environments demand standardized coding practices.
https://www.infoq.com/articles/platform-runtime-engineering/
Different teams are expected to be responsible for various services when applications grow. While cloud native is all about polyglot applications, it is normal to stick with a set of choices to standardize across teams, simplify the onboarding process of new members, and hire new team members. This standardization process across teams comes in the form of shared practices and, most of the time, libraries that all teams must use to build their services.
Architects will create conventions, APIs and define curated lists of dependencies that developers can use for their services. How these conventions, APIs, and dependencies are consumed and shared across teams is critical to their combined productivity.
Differences in cross-cutting behaviors such as authentication, authorization, resiliency policies, configurations (such as database connection pools, message brokers delivery policies, etc) and even logging can cause major headaches when running these applications at scale. These cross-cutting concerns affect not only libraries and configurations but also data. How do different services store data in other or the same database? How does each service manage the caching of this data or its structure? How is this data indexed? Do you need soft deletion or unified keys for compliance reasons?
As systems become larger and more complex we need to take the concepts of platform engineering to a higher level – to the code level – by creating platforms and abstractions that will reduce cognitive load, help simplify and accelerate software development, and allow for easy maintenance and upgrades to the platform.
https://www.infoq.com/articles/platform-runtime-engineering/
APIs and libraries that can solve common challenges for distributed systems and help teams follow well-known patterns can help them speed up complex decisions when creating scalable distributed applications.
Separating application dependencies from environment-specific configurations helps teams focus on what matters instead of cross-cutting concerns that only become relevant when their applications hit production environments.
New feature development, regardless of its size, can be significantly slowed by the need to address a multitude of cross-cutting concerns, such as network contracts, regulations, and various non-functional requirements that exist alongside core business needs.
https://www.infoq.com/articles/platform-runtime-engineering/
For our bank example, which conventions, patterns, and shared behaviors can these teams reuse so they don’t need to solve the same challenges twice? Some examples are Circuit Breakers, Retries mechanisms, Authentication/Authorization libraries, common configuration helpers, etc:

But applications also share common infrastructure-related dependencies such as database drivers or message broker clients:

Having a set of shared dependencies makes sense when systems like the ones described here start to grow. Teams use these dependencies to standardize how services implement shared concerns. From a platform perspective, it makes sense to push some of these concerns down to the environment where the application is running and expose these behaviors for developers to consume. The more of these cross-cutting concerns we can solve for developers, the more time they will have to focus on improving their applications.
Examples of libraries and tools that can help you in the process:
-
Libraries & patterns
- CloudEvents Specification to exchange events between applications
- Retry libraries and circuit breakers to increase application resiliency
- Distributed application patterns:
- Outbox pattern
- Saga Pattern (compensation actions to revert transactions)
- Distributed locks
-
Tools
- Dapr for developer-facing APIs and cloud-native best practices: The Dapr project offers APIs that developers can use to create highly scalable distributed applications. With Dapr, developers can interact with APIs instead of worrying about how to access complex infrastructure to develop day-to-day features. One of the most used Dapr APIs is the PubSub component, which enables services to exchange asynchronous messages while removing the complexities of adding specific message broker libraries and configurations to their applications. Once the applications are using the Dapr APIs, platform teams can define and configure which message broker will be used. This is followed by the Service-to-Service synchronous communication APIs that can be configured with resiliency policies, once again, without adding new language-specific libraries to their application code. Dapr provides SDKs in all major programming languages, so developers can interact with Dapr APIs using the tools they love. Check the following blog post to get more information about how Dapr is integrated with Spring Boot for Java and how it can be used with tools like Crossplane for a developer-focused platform engineering initiative.
- Feature Flagging with OpenFeature: With feature flagging, you can enable teams to release new features behind feature flags, reducing the risk of introducing new issues that will need to be reverted. OpenFeature follows the same approach as Dapr, providing SDKs in all major programming languages and abstracting away different feature flag providers so developers can focus on coding their features.
Platform engineering teams should strive to find opportunities to help development teams to standardize their practices. Here are some questions that can help the for platform engineering team to find these opportunities:
- Do you provide a curated list of shared libraries for development teams?
- Do you provide APIs for applications to use? Notice the difference between Platform APIs and APIs that interact with platform services.
- Do you provide guidelines on configuring services for local development and production scenarios?
Summing it up
Developer experience is already a trend in the cloud native industry, and I estimate it will grow by 2025. With this blog post, I’ve shared some challenges developers face when working with complex systems, which are not a top priority for platform engineering teams. It is crucial to note that sooner or later, teams will face these challenges, and the sooner they get addressed, the easier it will be for new team members to be onboarded, and developer satisfaction will increase. No matter if you are building distributed applications or monoliths, if developers are slowed down by learning complex tools and fighting with different environments’ configurations, there is an opportunity for the platform engineering team to improve and enable developers with a better experience.


